The State of Windows Support in Fluent Bit¶
- Author:
Fujimoto Seiji
- Published:
2019-07-17
- Copyright:
This document has been placed in the public domain.
This is my talk given on July 17 2019 at Fluentd Meetup, a collocated event of Open Source Summit Tokyo 2019
Many thanks to Eduardo Silva and Masahiro Nakagawa for inviting me to talk.
1. Introduction¶

|
I’m an engineer from ClearCode Inc. and right now working on the project to port Fluent Bit to Windows. Today I want to provide a general introduction of Fluent Bit and talk about the state of Windows support I’m working on. |
2. Log management problem¶

|
Let me start by saying that we have tons and tons of log data to manage, We have logs from app servers, logs from database servers, logs from proxy servers and so on. And the amount of logs is increasing very rapidly each year. |
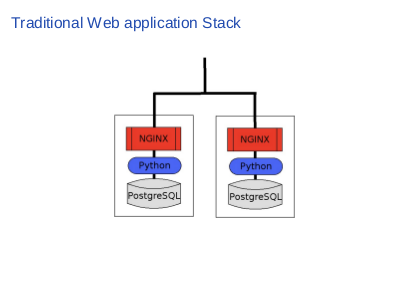
|
This is a traditional web application, which has two NGINX servers, two Python app servers and two PostgreSQL servers. The question is how many log files this stack contains? Let me count them up. First we have two access logs from NGINX of course, we have two app logs from Python application and two database logs from PostgreSQL. |
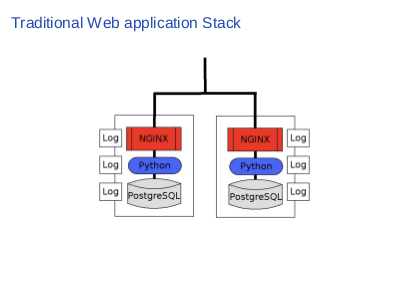
|
So we have at least six log files, all of which we need to monitor carefully, or we’ll miss serious incidents like connection limit exceeded, exception occurred and database replication failed etc. It’s already not a quite trivial task to monitor them properly. But things get better. |
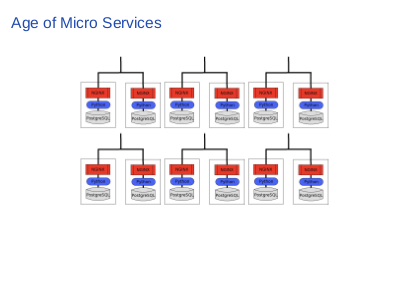
|
It’s age of micro services and virtualisation. Now you can literally have a dozen of severs just to run a single application, and every server emits log files independently with each other. In this slide now you have thirty six logs to manage, since you have six micro applications and each emits six logs. How do you monitor them? |

|
It’s no wonder that everyone suddenly rushes to log management solutions like Splunk, Elasticsearch, time series database like InfluxDB and message queues like Apache Kafka. I’m sure that you are using one or two of them at work. I for one use them at work. They are indeed amazing products. |
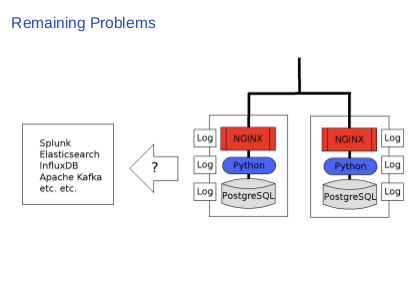
|
But the remaining problem here is “how do you send your logs to these products?” Your log files do not transfer themselves to other servers, so you need to make it happen. The question is “how”. |

|
I summarize my points so far. You have a large amount of log data at one hand, and you have amazing log management solutions at another hand. What is missing is a pipeline to connect them. |
3. Fluent Bit as a Solution¶

|
We develop Fluent Bit to solve this problem. Fluent Bit is a program that can talk a number of protocols and let you transfer |
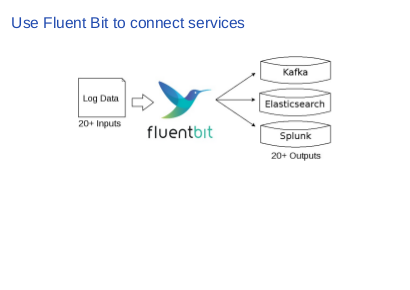
|
For example, it can speak Kafka protocol, so you can use Fluent Bit as a pipe to connect your data source to a Kafka cluster. Also it can speak Elasticsearch protocol, so you can ship logs into your Elasticsearch server. Fluent Bit supports more than twenty types of outputs, and twenty types of inputs. Thus, it is pretty much capable. |

|
At this point, you may wonder “Isn’t that what Fluentd exactly does? What is the difference with Fluentd?” The keyword is “efficiency”. As you may know, Fluentd is written in Ruby. It’s great and very convenient language but quite slower to run than compiled languages like C. Since Fluent Bit is written in C, it can process a lot more data efficiently than Fluentd. |
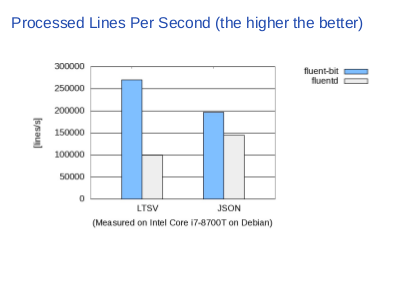
|
This table illustrates the difference between them. Blue is Fluent Bit, gray is Fluentd and Y-axis is the lines processed per second (the higher, the better). Talking about LTSV, Fluent Bit can process two times more data per second, so pretty much faster than Fluentd. Even with JSON, which Fluentd has a quite optimized parser for, but still Fluent Bit outperforms Fluentd by twenty or thirty percent. |
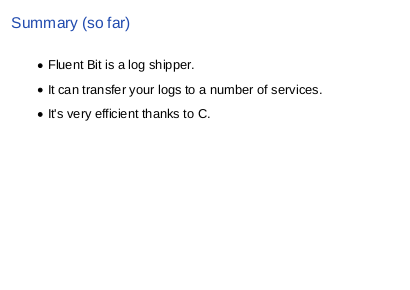
|
The summary so far is:
|
4. State of Windows Support¶

|
So this is the main part. First I’d like to talk a bit about the history of Fluent Bit. I’d like to start by telling that Fluent Bit was initially developed only for Linux, indeed only for embedded Linux at first. |

|
Five years ago, in the initial commit of Fluent Bit, the readme said “Fluent Bit is a collection tool designed for Embedded Linux that collects Kernel messages and Hardware metrics”. So that was the start. It was meant to be for Embedded Linux. |

|
Since then, we got full Linux support, OSX support and BSD support in 2015. We have also expand the supported architectures. Notably we have now full support for ARM 64 since two years ago. And this year we’ve gotten Fluent Bit to run on Windows. |
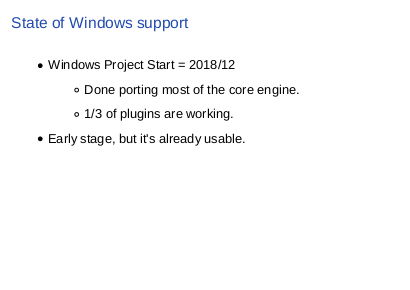
|
So what is the current status of Windows support? The porting project started the last December, so we have roughly six month’s work. It actually came along very smoothly. We’ve done porting most of core engine, and around third of plugins are working. It’s still quite an early stage, but the Windows port is already usable. |

|
More specifically, the works we’ve done are: we made it possible to compile Fluent Bit on MSVC, and enabled to launch Fluent Bit from PowerShell. Also we’ve done porting twenty plugins to Windows, and installers are also available in two flavours: EXE and ZIP, which make installation pretty much trivial. |
5. Tutorial for Windows Users¶

|
So I want to explain how you can use Fluent Bit today. This is very easy indeed, so I’d like to show how to do that in a step-by-step manner. |
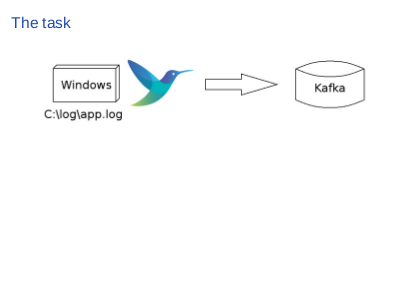
|
Let me first set up some context. Suppose you have some application running on Windows and the application outputs its logs to The task is to transfer the log file from Windows to Kafka. Using Fluent Bit, we can set up such a pipeline just in three steps. |
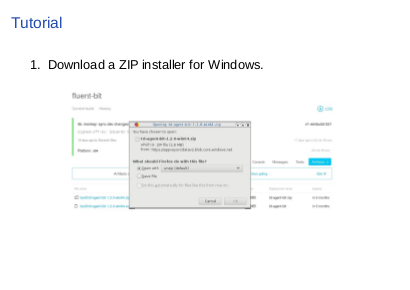
|
First, download the ZIP installer. We have EXE and ZIP installers as I said, and ZIP is easier for quick testing, so I use the one here. We build installers for each commit on AppVeyor. You can download from there if you want the latest one. Open the link on your browser and just click and save it. |
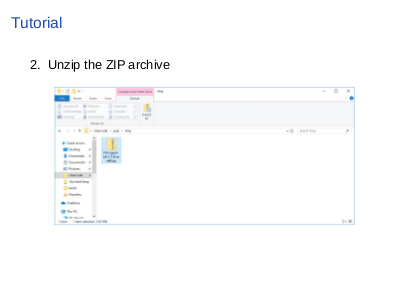
|
Next, expand the ZIP archive. You need to just click the ZIP archive and select “Expand All” on Explorer or you can use the “Expand-Archive” commandlet on PowerShell. Both work fine, so choose the one you like. |

|
Then open PowerShell and just launch Fluent Bit. The ZIP file contains fluent-bit.exe which is a stand-alone binary. As you can see in the slide, it is included in the bin directory |

|
As I said, the target log file is stored in We use tail plugin as an input, and set the path accordingly. |

|
And we assumed that the output is Apache Kafka. We use the Kafka output plugin, set broker’s IP address and tell Fluent Bit to send the data with “windows” topic That’s it! You should see log lines running to your Kafka server. Alternatively, you can create a configuration file and feed it to Fluent Bit via -c option. You can download a sample configuration file here. |

|
The summary is:
This is all that you need. Please try at home if you have some interest in Fluent Bit, and please give us some feedback. |
6. Future of Fluent Bit¶

|
So this is status of our efforts to make Fluent Bit Windows-compatible log shipping solution. I’d like to finish my talk with sharing some ideas of future development. |

|
First I’m planning to port the remaining thirty two plugins to Windows as much as possible. As to the plugin, we are right now working on a plugin for Windows Event Log which should be useful for Windows administrators. And I’m planning to add more documents, since it’s kinda sparse right now. |
|
And we need feedbacks from users! What is your use case? Which service do you want to connect to? If you have idea please tell us on the issue tracker on GitHub. I’d like to hear from you. Thank you. |